🗣 서론
KOCW 반효경 교수님의 운영체제 수업을 들으면서 작성한 글입니다.
동기식 입출력과 비동기식 입출력, 저장장치 계층 구조, 프로그램의 실행, 프로그램의 실행(메모리 load), 시스템 콜(System Call), DMA(Direct Memory Access), 서로 다른 입출력 명령어, 커널 주소 공간의 내용, 사용자 프로그램이 사용하는 함수
📌 동기식 입출력과 비동기식 입출력

동기식 입출력 (synchronous I/O)
I/O 요청 후 입출력 작업이 완료된 후 제어가 사용자 프로그램에 넘어간다.
[구현 방법 A]
- I/O 요청을 후 끝날 때까지 기다리면, CPU를 낭비시킨다.
- 매 시점 하나의 I/O만 일어날 수 있다.
-> CPU를 낭비시키는 구현 방법
[구현 방법 B]
- I/O 요청 후 완료될 때까지 해당 프로그램의 CPU를 뺐는다.
- I/O 처리를 기다리는 줄에 해당 프로그램을 줄 세운다.
- 다른 프로그램에게 CPU를 준다.
-> 보통 동기식 입출력은 구현 방법 B
비동기식 입출력 (asynchronous I/O)
I/O가 시작된 후 입출력 작업이 끝나기를 기다리지 않고, CPU 제어권을 사용자 프로그램에 즉시 넘긴다.
[질문] I/O의 완료는 어떻게 알리는가?
동기식, 비동기식 입출력 모두 인터럽트로 I/O의 완료를 알린다.
📌 DMA(Direct Memory Access)
1. 빠른 입출력 장치를 메모리에 가까운 속도로 처리하기 위해 사용한다.
(인터럽트를 빈번히 걸면 CPU가 많은 인터럽트로 인해 문제가 생길 수 있다. 따라서 중간에 DMA Controller가 직접 메모리에 접근하여 카피한다)
2. CPU의 중재 없이 device controller가 device의 buffer storage의 내용을 메모리에 block 단위로 직접 전송한다.
3. 바이트 단위가 아니라 block 단위로 인터럽트를 발생시킨다.
DMA는 1바이트가 들어왔다고 CPU에 인터럽트를 거는 게 아니다.
버퍼에 쌓인 데이터를 DMA가 메모리에 카피를 하고, 버퍼에 특정 크기(block 단위)만큼 데이터가 쌓이면 인터럽트를 발생시킨다.
📌 서로 다른 입출력 명령어
I/O는 일반적인 I/O 방식과 Memory Mapped I/O 방식이 있다.

일반적인 I/O
메모리 접근하는 인스트럭션과 I/O장치를 접근해야 하는 인스트럭션(special instruction)이 따로 있다.
Memory Mapped I/O
I/O 장치도 메모리 주소에 연장 주소를 붙여 접근할 수 있다.
예를 들어 100번지에 접근하면 메모리에 접근한다면, 1000번지에 해당하는 메모리에 접근하는 인스트럭션은 사실은 I/O를 하는 인스트럭션을 뜻할 수 있다.
📌 저장장치 계층 구조

위로 갈수록 속도가 빠르지만, 단위 공간당 가격이 비싸고 용량이 적다.
아래로 갈수록 가격은 싸고 용량이 많지만, 속도가 느려진다.
휘발성 비휘발성? (Volatility)
휘발성 매체는 전원이 나가면 데이터가 사라진다.
비휘발성 매체는 전원이 나가도 데이터는 사라지지 않는다.
Primary, Secondary storage?
CPU는 바이트 단위로 접근 가능한 매체이어야 접근이 가능하다.
[Primary]
CPU에서 직접 접근할 수 있는 매체를 말한다. Executable(실행 가능하다)하다고 한다.
즉, 위 그룹(초록)은 바이트 단위로 CPU 접근이 가능하며 이것을 Primary라고 부른다.
[Secondary]
CPU가 직접 접근하지 못하는 매체를 말한다.
하드디스크의 단위는 섹터 단위로 접근할 수 있어 CPU가 접근하지 못하며 이것을 Secondary라고 부른다.
캐시 메모리가 있는 이유?
CPU와 메인 메모리의 속도 차이를 완충하기 위해 캐시 메모리를 둔다.
용량이 적기 때문에 모든 걸 담아 둘 수는 없다. (기존에 있던걸 없애야 하는데 이는 나중에 이야기하도록 한다)
캐싱은 재사용을 목적으로 한다. 즉, 두 번째 요청부터 이미 읽어온 데이터를 사용하게 된다.
📌 프로그램은 어떻게 실행되는가?
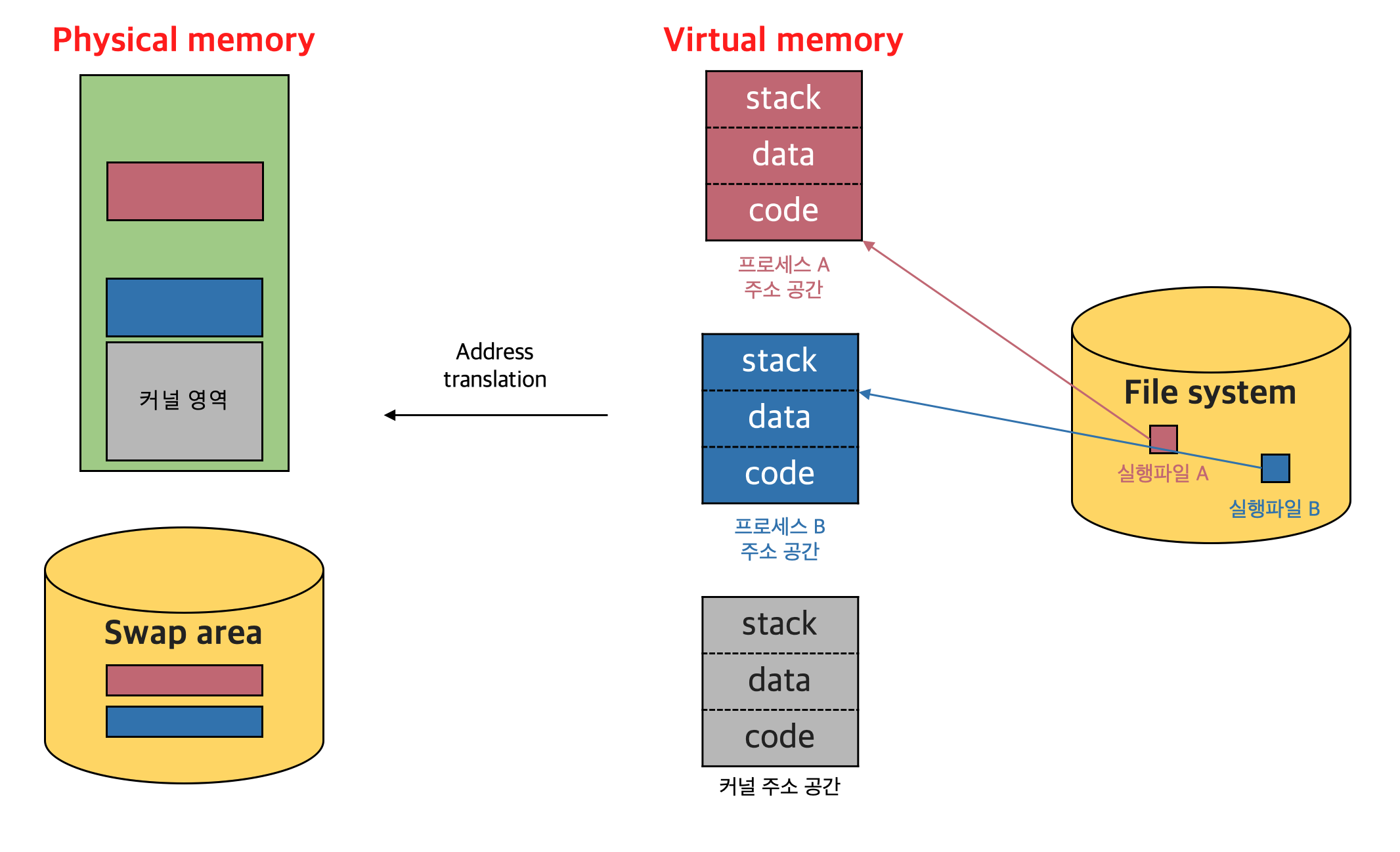
프로그램은 File System에 실행 파일 형태로 저장되어 있다. 실행시키게 되면 메모리에 올라가 프로세스가 된다.
정확히 물리적인 메모리에 바로 올라가는 것이 아니라 한 단계를 거치게 되는데 이를 가상 메모리(Virtual Memory) 단계를 거친다고 한다.
이때 독자적인 메모리 주소 공간이 형성되는데 code, data, stack 영역으로 구성되어 있다.
[code] CPU에서 실행할 기계어 코드를 저장
[data] 변수를 저장
[stack] 함수를 호출하거나 리턴할 때 데이터를 쌓았다가 꺼냄
물리적인 메모리에 올려서 실행시키는데 프로그램을 실행시켰을 때 만들어진 주소 공간을 물리적인 메모리에 통째로 올리는 것은 아니다. 통째로 올리면 메모리를 낭비될 수 있다. 그래서 필요한 부분만 올리게 된다.
Virtual Memory?
사용하지 않으면 메모리에서 쫓아 버리는 게 아니라 Disk에 내려놓게 된다. (이러한 용도의 공간을 Swap area라고 한다)
즉, 주소 공간을 쪼개서 어떤 부분은 메모리에 있고, 어떤 부분은 Swap area에 있게 된다.
이런 기법을 Virtual Memory라고 부르기도 하지만, 사실 각 프로그램마다 독자적으로 가지고 있는 메모리 주소 공간을 Virtual Memory라고 한다.
[Disk 활용]
Disk의 Swap area는 메모리 연장 공간(휘발성)으로 사용하고, File System은 비휘발성 용도로 사용한다.
주소 공간에서 1000번지인데 물리적인 메모리에는 3000번지로 올라가던지 즉, 다른 번지로 저장될 수 있다.
이를 주소 변환 계층에서 한다. (Address translation, 변환하는 하드웨어 장치가 있는데 자세한 부분은 메모리 관리 부분에서 다룰 예정)
📌 커널 주소 공간의 내용

code
- 운영체제는 시스템 자원을 효율적으로 관리하는 역할을 하는데 이때 관련된 코드가 해당 영역에 있다.
- 사용자에게 편리한 서비스를 제공하기 위한 코드가 있다.
- 인터럽트마다 무슨 일을 처리해야 하는지 함수 형태로 구현되어 있다.
data
운영체제가 사용하는 자료구조가 정의되어 있다.
[PCB(Process Control Block)]
- 프로세스를 관리하는 자료구조
- 프로세스마다 하나씩 존재
stack
- 함수를 호출하거나 리턴할 때 stack 영역을 이용한다.
- 어떤 프로세스가 커널의 코드를 실행 중인가에 따라 프로세스마다 커널 스택을 별도로 가진다.
📌 사용자 프로그램이 사용하는 함수

사용자 정의 함수
자신의 프로그램에서 정의한 함수를 말한다.
라이브러리 함수
- 자신의 프로그램에서 정의하지 않고, 가져다 사용한 함수를 말한다.
- 자신의 프로그램의 실행 파일에 포함되어 있다.
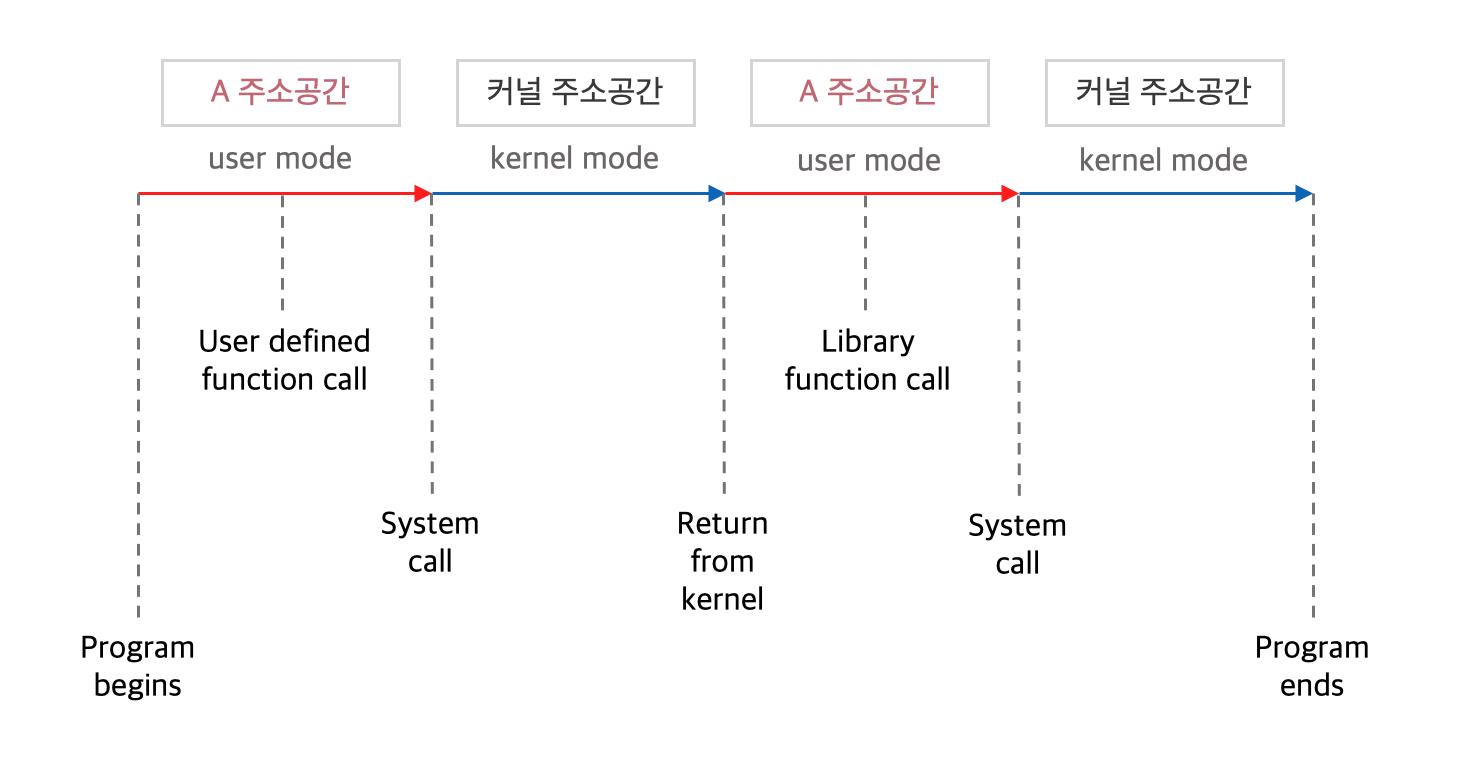
커널 함수
- 운영체제 프로그램의 함수를 말한다.
- 커널 함수의 호출 = 시스템 콜
(주소 점프를 할 수 없기 때문에 인터럽트 라인을 세팅해서 CPU 제어권을 넘겨야 한다)
📌 프로그램의 실행
반효경 [운영체제] 4. System Structure & Program Execution 2
설명이 없습니다.
core.ewha.ac.kr
운영체제
운영체제는 컴퓨터 하드웨어 바로 위에 설치되는 소프트웨어 계층으로서 모든 컴퓨터 시스템의 필수적인 부분이다. 본 강좌에서는 이와 같은 운영체제의 개념과 역할, 운영체제를 구성하는 각
www.kocw.net
'OS' 카테고리의 다른 글
| 💻 KOCW-OS-4: Process (0) | 2020.10.26 |
|---|---|
| 💻 KOCW-OS-2: System Structure & Program Execution 1 (0) | 2020.10.04 |
| 💻 KOCW-OS-1: Introduction to Operating Systems (0) | 2020.10.03 |


